:kr: 다크넷(darknet): 윈도우와 리눅스를 위한 욜로-v3(yolo-v3)과 욜로-v2(yolo-v2)
출처:
- https://github.com/AlexeyAB/darknet
| 다크넷 | 설치 | 욜로 | 이미지넷분류 | 악몽 | 재사용신경망 | 다크고 | 꼬맹이망 | 분류기벼림 | 사용방법 |
| — | — | — | — | — | — | — | — | — | — |

다크넷(darknet): 윈도우와 리눅스를 위한 욜로-v3(yolo-v3)과 욜로-v2(yolo-v2)
(개체 검출을 위한 신경망) - 텐서코어를 리눅스와 윈도우에서 사용할 수 있다.
이 글은 https://github.com/AlexeyAB/darknet 에 작성된 욜로-사용방법만 번역한 것이다.
자신이 사용할 원본은 https://github.com/AlexeyAB/darknet 주소에서 갈라치길 바란다.
#### 나는 한번만 본다(YOLO): 통합된, 실시간 개체검출(판 2와 3)
- 이 저장소에서 개선 내용
- 사용 방법
- 리눅스에서 컴파일하는 방법
- 윈도우에서 컴파일하는 방법
- 벼림하는 방법(물리 시각개체분류 자료, Pascal VOC)
- 벼림하는 방법(사용자가 정한 개체를 검출하기 위하여)
- 언제 벼림을 중지해야 하는가
- 물리 시각개체분류(Pascal VOC)로 mAP를 계산하는 방법
- 개체검출을 개선하는 방법
- 개체의 경계상자를 표시하고 설명파일을 생성하는 방법
- 욜로9000(Yolo9000) 사용
- DLL로 욜로를 사용하는 방법
| <p align="center"> </p> |
</p> | 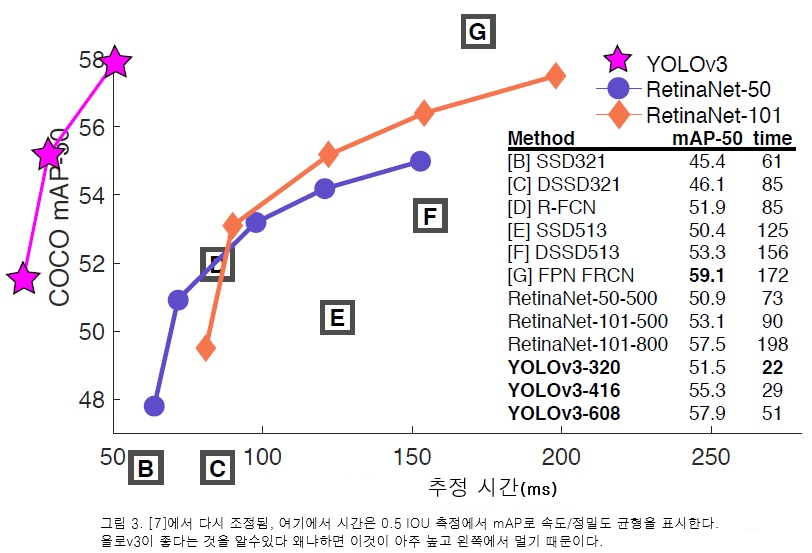 mAP (AP50) https://pjreddie.com/media/files/papers/YOLOv3.pdf |
mAP (AP50) https://pjreddie.com/media/files/papers/YOLOv3.pdf |
| — | — |
- YOLOv3 보다 YOLOv3-spp가 우수하다(표시되지 않음) - mAP = 60.6%, FPS = 20: https://pjreddie.com/darknet/yolo/
- 마이크로소프트 코코(MS COCO)의 RetinaNet에 대한 욜로-v3(Yolo-v3) 원본 챠트는 표1(Table 1)에서 확인함 (e): https://arxiv.org/pdf/1708.02002.pdf
- 물리 시각개체분류 2007로 욜로-v2: https://hsto.org/files/a24/21e/068/a2421e0689fb43f08584de9d44c2215f.jpg
- 물리 시각개체분류 2012로 욜로-v2(comp4): https://hsto.org/files/3a6/fdf/b53/3a6fdfb533f34cee9b52bdd9bb0b19d9.jpg
#### 나는 한번만 본다(YOLO): 통합된, 실시간 개체검출(판 2와 3)
윈도우와 리눅스판 욜로 혼합-작업대(cross-platform), 개체검출을 위한.
도우미: https://github.com/AlexeyAB/darknet/graphs/contributors
이 저장소는 리눅스판에서 갈라졌다: https://github.com/pjreddie/darknet
자세한 내용: :kr:여기는 국문, 여기는 영문
- 윈도우와 리눅스 모두
- OpenCV 2.x.x 와 OpenCV <= 3.4.0 (3.4.1 이상은 지원 안됨, 하지만 시도할 수 있다)
- cuDNN >= v7 이상
- CUDA >= 7.5 이상
- 또한 리눅스용 개체공유-라이브러리(SO-library, Shared Object Library) 와 윈도우용 동적연결-라이브러리(DLL, Dynamic Linking Library) 생성
- 리눅스 GCC>=4.9 또는 윈도우 마리크로소프트 비주얼 스튜디오 2015 (v140): https://go.microsoft.com/fwlink/?LinkId=532606&clcid=0x409 (또는 독립설치 ISO 이미지)
- CUDA 10.0: https://developer.nvidia.com/cuda-toolkit-archive (리눅스에서 기반-설치 하기를 한다)
- OpenCV 3.3.0: https://sourceforge.net/projects/opencvlibrary/files/opencv-win/3.3.0/opencv-3.3.0-vc14.exe/download
- 또는 OpenCV 2.4.13: https://sourceforge.net/projects/opencvlibrary/files/opencv-win/2.4.13/opencv-2.4.13.2-vc14.exe/download
- OpenCV는 이미지 또는 동영상 검출을 보여줄 수 있다 그리고 명령줄에
-out_filename 출력파일.avi로 지정된 파일로 결과를 저장한다.
- OpenCV는 이미지 또는 동영상 검출을 보여줄 수 있다 그리고 명령줄에
- GPU 의 연산능력(Compute Capability) >= 3.0: https://en.wikipedia.org/wiki/CUDA#GPUs_supported
그곳에 구성(cfg)파일 각각에 대한 가중값(weights)파일이 있다(작은크기 -> 빠른 속도와 낮은 정밀도 순으로):
yolov3-openimages.cfg(247 MB COCO Yolo v3) - 4 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov3-openimages.weightsyolov3-spp.cfg(240 MB COCO Yolo v3) - 4 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov3-spp.weightsyolov3.cfg(236 MB COCO Yolo v3) - 4 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov3.weightsyolov3-tiny.cfg(34 MB COCO Yolo v3 tiny) - 1 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov3-tiny.weightsyolov2.cfg(194 MB COCO Yolo v2) - 4 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov2.weightsyolo-voc.cfg(194 MB VOC Yolo v2) - 4 GB GPU-RAM 필요: http://pjreddie.com/media/files/yolo-voc.weightsyolov2-tiny.cfg(43 MB COCO Yolo v2) - 1 GB GPU-RAM 필요: https://pjreddie.com/media/files/yolov2-tiny.weightsyolov2-tiny-voc.cfg(60 MB VOC Yolo v2) - 1 GB GPU-RAM 필요: http://pjreddie.com/media/files/yolov2-tiny-voc.weightsyolo9000.cfg(186 MB Yolo9000) - 4 GB GPU-RAM 필요: http://pjreddie.com/media/files/yolo9000.weights
이것(가중값파일)은 컴파일된 근처에 넣어라: darknet.exe
구성(cfg)파일을 얻을수 있는 경로: darknet/cfg/
“모든것이 놀랍다!”

다른것: https://www.youtube.com/channel/UC7ev3hNVkx4DzZ3LO19oebg
0. 이 저장소에서 개선 내용
- 윈도우에 대한 지원 추가
- CPU와 GPU로 검출에 대해 이진 신경망 성능이 2x-4x 배 개선됨. XNOR-net 모형(bit-1 추정)으로 자신의 가중값을 벼림한 경우: https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny_xnor.cfg
- 2단을 1단으로 결합하여 신경망 성능이 ~7% 까지 개선됨: 나선(Convolutional) + 동이-고름(Batch-norm)
- 텐서코어 사용한 볼타(Tesla V100, Titan V, …) GPU에서 신경망 성능이 검출에 2x 배, 벼림에 3x 배 개선됨.
Makefile또는darknet.sln에서CUDNN_HALF가 정의된 경우 darknet detector demo등을 사용 동영상(파일/뭉치, stream) 검출에 대하여, FullHD에서 ~1.2x배, 4K에서 ~2x배 성능 개선됨- 벼림을 위한 자료증대 3.5x배 성능 개선됨(직접 작성한 함수 대신 OpenCV SSE/AVX 함수를 사용하여) - 다중-GPU 또는 볼타-GPU로 벼림을 위한 병목현상 제거
- AVX를 가진 인텔 CPU로 검출과 벼림성능이 개선됨(Yolo v3 ~85%, Yolo v2 ~10%)
[reorg]-단 사용법 수정random=1일때 망을 재조정하는 동안 최적화된 메모리 할당- 검출을 위하여 GPU 초기화 최적화됨 - batch=1로 다시-초기화를 하는 대신에 처음에 batch=1을 사용
darknet detector map등을 사용 mAP, F1, IoU, Precision-Recall 계산 보정 추가- 벼림하는 동한 평균손실 챠트그리기 추가
- 벼림을 위한 고정자(anchor)계산 추가
- 개체 검출과 추적 본보기 추가: https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp
- OpenCV 3.x로 웹캠 사용을 위하여 코드 수정
- 실시간 조언과 경고. 잘못된 구성(cfg)파일 또는 자료집합을 사용하는 경우.
- 다른 많은 코드 수정…
그리고 사용방법 추가 - 욜로 v3/v2 벼림방법
1. 사용 방법
* 명령줄로 사용하는 방법
리눅스상에서 darknet.exe대신에 ./darknet을 사용한다, 이것 처럼: ./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights
- Yolo v3 COCO - 이미지:
darknet.exe detector test data/coco.data cfg/yolov3.cfg yolov3.weights -i 0 -thresh 0.25 - 개체 출력 좌표:
darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights -ext_output dog.jpg - Yolo v3 COCO - 동영상:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -ext_output test.mp4 - Yolo v3 COCO - 웹캠 0:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -c 0 - 네트워크-동영상카메라를 위한 Yolo v3 COCO - 스마트폰 웹캠:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg - Yolo v3 - 결과.avi 파일로 결과 저장:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 test.mp4 -out_filename 결과.avi - Yolo v3 꼬맹이 COCO - 동영상:
darknet.exe detector demo data/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights test.mp4 - 0번 GPU로 Yolo v3 꼬맹이 :
darknet.exe detector demo data/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -i 0 test.mp4 - Yolo v3 COCO 다른 방법 - 이미지:
darknet.exe detect cfg/yolov3.cfg yolov3.weights -i 0 -thresh 0.25 - 186 MB Yolo9000 - 이미지:
darknet.exe detector test cfg/combine9k.data yolo9000.cfg yolo9000.weights - 자신의 응용프로그램과 동일 폴더 아래에 data/9k.tree와 data/coco9k.map을 넣는것을 잊지마라. cpp api를 사용하여 응용프로그램을 빌드하는 경우.
- 처리하기 위한 이미지 목록은
data/train.txt그리고 검출 결과를 저장하기 위하여result.txt를 사용:
darknet.exe detector test cfg/coco.data yolov3.cfg yolov3.weights -dont_show -ext_output < data/train.txt > result.txt - 고정기(anchor) 계산을 위하여:
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 - mAP50 정밀도를 확인하기 위하여:
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights
* 모든 안드로이드 스마트폰을 가지고 네트워크 동영상-카메라 mjpeg-뭉치(stream) 사용을 위하여
- 안드로이드폰 mjpeg-뭉치(stream) 소프트웨어 내려받기: IP 웹캠 / 스카트 웹캠
- 스마트 웹캠 - 선호함: https://play.google.com/store/apps/details?id=com.acontech.android.SmartWebCam2
- IP 웹캠: https://play.google.com/store/apps/details?id=com.pas.webcam
-
와이파이(WiFi, 와이파이-라우터를 통해) 또는 유에스비(USB)를 통해 컴퓨터에 자신의 스마트폰을 연결한다
-
자신의 웹캠으로 스마트 웹캠을 시작한다
-
아래의 주소를 대체한다, 스마트폰 응용프로그램(Smart WebCam)에 보이는 주소로, 그리고 실행한다:
- Yolo v3 COCO-모형:
darknet.exe detector demo data/coco.data yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg -i 0
2. 리눅스에서 컴파일하는 방법
다크넷 디렉토리에서 직접 make를 한다. make 전에, Makefile에서 옵션같은 것을 설정할수 있다: 연결
GPU=1로 빌드하면 GPU 사용하여 가속하기 위한 CUDA를 포함한다(/usr/local/cuda에 CUDA가 있어야 한다)CUDNN=1로 빌드하면 GPU 사용하여 벼림가속을 위한 cuDNN v5-v7를 포함한다(/usr/local/cudnn에 cuDNN이 있어야 한다)CUDNN_HALF=1로 빌드하면 텐서코어에 대해(Titan V, Tesla V100, DGX-2 그리고 계승된것) 검출 3x, 벼림 2x 가속됨OPENCV=1로 빌드하면 OpenCV 3.x/2.4.x를 포함한다 - 동영상파일과 네트워크 카메라 또는 웹캠으로부터 동영상뭉치로 검출할수 있다DEBUG=1로 빌드하면 욜로판을 디버그할수 있다OPENMP=1로 빌드하면 다중-코어 CPU를 사용하여 가속하기 위한 OpenMP 지원을 포함한다LIBSO=1로 빌드하면darknet.so라이브러리를 만든다 그리고 이진 실행가능 파일은uselib로 이 라이브러리를 사용한다. 또는LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib test.mp4로 할수 있다. 자신의 코드에서 개체공유-라이브러리(SO-library)를 사용하는 방법은 - C++ 본보기에서 볼수 있다: https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp 또는 이런 방법으로 사용한다:LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov3.cfg yolov3.weights test.mp4
리눅스에서 다크넷을 실행하려면 이글의 본보기를 사용하라, darknet.exe대신에 단지 ./darknet를 사용한다, 예를들어 이 명령을 사용한다: ./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights
3. 윈도우에서 컴파일하는 방법
MSVS : MicroSoft Visual Studio, 마이크로소프트 비주얼스튜디오
CUDA : Compute Unified Device Architecture, 연산이 통합된 장치구조
OpenCV : Open source Computer Vision, 영상계산(컴퓨터영상처리) 자원 공개
- 만약 MSVS 2015, CUDA 10.0, cuDNN 7.4 와 OpenCV 3.x 를 가지고 있다면(포함 경로:
C:\opencv_3.0\opencv\build\include그리고C:\opencv_3.0\opencv\build\x64\vc14\lib), 그러면 마이크로소프트 비주얼스튜디오를 시작한다,build\darknet\darknet.sln를 연다, x64 와 Release 로 설정한다 그리고빌드->darknet 빌드를 실행한다. 또한 윈도우 시스템변수cudnn에 CUDNN 의 경로를 추가한다: 참조그림
알림: 만약 OpenCV를 설치한다면, OpenCV 3.4.0 또는 이전버전을 사용하라. 이것은 C 응용프로그램의 OpenCV 3.4.1에서 버그다(500번을 보라).
{kind=link}
{kind=link}
1-1) C:\opencv_3.0\opencv\build\x64\vc14\bin에 있는 opencv_world320.dll과 opencv_ffmpeg320_64.dll(또는 opencv_world340.dll과 opencv_ffmpeg340_64.dll) 파일을 찾는다 그리고 darknet.exe이 포함된 근처에 넣는다.
1-2) C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0안에 bin과 include폴더가 있는지 확인한다. 그렇지 않으면, CUDA가 설치된 경로에서 이 폴더로 복사를 한다.
1-3) CUDNN을 설치하려면(신경망 속도증가), 다음을 수행한다:
1-4) 만약 CUDNN 없이 빌드를 원한다면: \darknet.sln을 열고 -> 프로젝트 -> 속성 -> C/C++ -> 전처리기 -> 전처리기 정의에서, CUDNN을 제거한다.
-
다른 버전의 CUDA(10.0 아님) 를 가졌다면 문서편집기를 사용하여
build\darknet\darknet.vcxproj를 연다, “CUDA 10.0”이 포함된 2곳을 찾는다 그리고 자신의 버전으로 변경한다, 그런다음 단계1을 수행한다. -
만약 GPU가 없다 면, 하지만 MSVS 2015 와 OpenCV 3.0 (포함경로:
C:\opencv_3.0\opencv\build\include와C:\opencv_3.0\opencv\build\x64\vc14\lib)가 있다, 그러면 마이크로소프트 비주얼스튜디오를 시작하고,build\darknet\darknet_no_gpu.sln를 열고, x64 와 Release 로 설정한다, 그리고빌드->darknet_no_gpu 빌드를 한다. -
만약 OpenCV 3.0 대신에 OpenCV 2.4.13 을 가지고 있다 그러면
\darknet.sln을 열고나서 경로를 변경해야 한다
4-1) 프로젝트 -> 속성 -> C/C++ -> 일반 -> 추가 포함 디렉토리에 추가: C:\opencv_2.4.13\opencv\build\include
4-2) 프로젝트 -> 속성 -> 링커 -> 일반 -> 추가 라이브러리 디렉토리에 추가: C:\opencv_2.4.13\opencv\build\x64\vc14\lib
- 만약 검출에 3x, 벼림에 2x 가속 텐서코어(nVidia Titan V, Tesla V100, DGX-2 그리고 계승된것)를 가진 GPU를 가졌다면:
\darknet.sln을 열고, 프로젝트 -> 속성 -> C/C++ -> 전처리기 -> 전처리기 정의에,CUDNN_HALF를 추가한다.
알림: CUDA는 반드시 마이크로소프트 비주얼스튜디오 2015가 설치된 후에 설치해야 한다.
3-1. 윈도우에서 컴파일하는 방법(맞춤)
또한, 자신의 darknet.sln과 darknet.vcxproj를 생성할수 있다, 이 본보기는 CUDA 9.1과 OpenCV 3.0에 대한 본보기다.
그런다음 생성된 자신의 프로젝트에 추가한다:
-
프로젝트 -> 속성 -> C/C++ -> 일반 -> 추가 포함 디렉토리에 넣는다:
C:\opencv_3.0\opencv\build\include; ..\..\3rdparty\include; %(AdditionalIncludeDirectories); $(CudaToolkitIncludeDir); $(cudnn)\include -
솔루션 탐색기 탭에서 프로젝트 이름(예: darknet)을 마우스 오른쪽버튼을 눌러 튀어오름 메뉴에서
빌드 종속성->사용자 지정 빌드를 클릭하고, 열린 창에서 CUDA 9.1 또는 자신이 가진 판을 선택지정한다. -
\src에서 모든.c와.cu파일과http_stream.cpp파일을 프로젝트에 추가한다. -
프로젝트 -> 속성 -> 링커 -> 일반 -> 추가 라이브러리 디렉토리에 추가:
C:\opencv_3.0\opencv\build\x64\vc14\lib; $(CUDA_PATH)lib\$(PlatformName); $(cudnn)\lib\x64; %(AdditionalLibraryDirectories) -
프로젝트 -> 속성 -> 링커 -> 입력 -> 추가 종속성에 추가:
..\..\3rdparty\lib\x64\pthreadVC2.lib; cublas.lib; curand.lib; cudart.lib; cudnn.lib; %(AdditionalDependencies) -
프로젝트 -> 속성 -> C/C++ -> 전처리기 -> 전처리기 정의에 추가:
OPENCV; _TIMESPEC_DEFINED; _CRT_SECURE_NO_WARNINGS; _CRT_RAND_S; WIN32; NDEBUG; _CONSOLE; _LIB; %(PreprocessorDefinitions) -
.exe (X64 와 Release)로 컴파일한다 그리고 .exe 근처에 .dll을 넣는다:
\3rdparty\dll\x64에서pthreadVC2.dll, pthreadGC2.dllC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin에서, CUDA 9.1을 위한 91 또는 자신의 판cusolver64_91.dll, curand64_91.dll, cudart64_91.dll, cublas64_91.dll- OpenCV 3.2를 위하여:
C:\opencv_3.0\opencv\build\x64\vc14\bin에서opencv_world320.dll과opencv_ffmpeg320_64.dll - OpenCV 2.4.13를 위하여:
C:\opencv_2.4.13\opencv\build\x64\vc14\bin에서opencv_core2413.dll과opencv_highgui2413.dll
{kind=link}
{kind=link}
4. 벼림하는 방법(물리 시각개체분류 자료, Pascal VOC)
-
http://pjreddie.com/media/files/darknet53.conv.74 에서 나선단에 대한 미리-벼림된 가중값(154 MB)을 내려받는다: 그리고
build\darknet\x64에 넣는다. -
Pascal VOC 자료를 내료받고
build\darknet\x64\data\voc폴더에 묶음을 푼다 이것은build\darknet\x64\data\voc\VOCdevkit\폴더가 생성된다:
- http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
- http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
- http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
2-1) build\darknet\x64\data\voc폴더에 voc_label.py파일을 내려받는다: http://pjreddie.com/media/files/voc_label.py
-
윈도우를 위한 파이썬을 내려받고 설치한다: https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe
-
명령을 실행한다:
python build\darknet\x64\data\voc\voc_label.py(이것은 2007_test.txt, 2007_train.txt, 2007_val.txt, 2012_train.txt, 2012_val.txt 파일을 생성하기위한 것이다) -
명령을 실행한다:
type 2007_train.txt 2007_val.txt 2012_*.txt > train.txt(이것은 위에서 생성한 파일을 하나의 2007_train.txt 파일로 합치는 것이다) -
yolov3-voc.cfg파일(의 3행, 4행을)에서batch=64와subdivisions=8로 설정한다: 연결 -
train_voc.cmd를 사용하여 벼림을 시작한다 아니면 명령행을 사용한다:
darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
( 알림: 손실-창을 해제하기 위해서는-dont_show표기를 사용한다. 만약 CPU 벼림은darknet.exe대신에darknet_no_gpu.exe을 사용한다. )
만약 필요한 경우 build\darknet\x64\data\voc.data 파일에서 경로를 변경한다.
벼림에 대한 추가정보는 연결로… : :kr:국문, 영문
알림: 만약 벼림하는 동안 avg(손실, 오차) 영역에 대하여 nan값을 봤다 - 그러면 벼림이 잘못된 것이다, 하지만 만약 nan이 다른 행에 있다 - 그러면 벼림이 잘 되는 것이다.
4-2. 다중-GPU를 가지고 벼림하는 방법
-
먼저 약 1000번 반복에 대해 하나의 GPU로 벼림한다:
darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -
그런다음 중지한다 그리고 약간 벼림된 모형
/backup/yolov3-voc_1000.weights을 사용하여 다중GPU를 가지고 벼림을 한다(4개의 GPU 까지):
darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights -gpus 0,1,2,3
적은 자료집합의 경우는 때대로 학습률을 줄이는 것이 더 좋다, 4 GPU 집합에 대하여 learning_rate = 0.00025(즉, learning_rate = 0.001/GPU수). 이 경우 또한 자신의 구성파일(.cfg 파일)에서 burn_in =을 max_batches =의 4x 배로 늘린다. 즉, 1000 대신에 burn_in = 4000을 사용한다.
https://groups.google.com/d/msg/darknet/NbJqonJBTSY/Te5PfIpuCAAJ
5. 벼림하는 방법(사용자가 정한 개체를 검출하기 위하여)
( 이전의 욜로-v2를 벼림하기 위해서는 yolov2-voc.cfg, yolov2-tiny-voc.cfg, yolo-voc.cfg, yolo-voc.2.0.cfg, … :kr:국문, 영문 )
욜로-v3 벼림:
yolov3.cfg와 같은 내용으로yolo-obj.cfg파일을 생성한다(또는yolov3.cfg를yolo-obj.cfg로 복사) 그리고:
- batch 행을
batch=64로 변경한다 - subdivisions 행읗
subdivisions=8로 변경한다 classes=80행을 3개의[yolo]-단에서 자신의 개체개수로 변경한다:- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L610
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L696
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L783
- [
filters=255] 행을 각[yolo]단 이전 3개의[convolutional]단에 filters=(classes + 5)x3 로 변경한다:- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L603
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L689
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L776
그러므로 만약 classes=1이면 filters=18이 된다. 만약 classes=2이면 filters=21로 쓴다.
( 구성파일에 filters=(classes + 5)x3) 로 쓰지 마라! )
( 일반적으로 filters는 classes, coords와 mask의 개수에 종속된다, 즉, filters=(classes + coords + 1)*<number of mask>, 여기에서 mask는 고정자(anchor)의 순번(index)이다. 만약 mask가 없다, 그러면 filters=(classes + coords + 1)*num 이다 )
그래서 본보기에 대해, 2개의 개체를 위해, 자신의 yolo-obj.cfg파일은 [yolo]단 3개 각각의 행이 아래처럼 yolov3.cfg와 달라야 한다:
[convolutional]
filters=21
[region]
classes=2
-
build\darknet\x64\data\폴더에obj.names파일을 생성한다, 개체 이름을 가진 - 다른 행에 각각 -
build\darknet\x64\data\폴더에obj.data파일을 생성한다, (여기에서 classes = 개체 개수)를 담고있는
classes= 2
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
-
build\darknet\x64\data\obj\폴더에 자신의 개체 이미지파일(.jpg)을 넣는다 -
자신의 자료집합인 이미지에 개체 각각의 딱지(label)를 지정해야 한다. 개체의 경계상자 표식과 설명파일을 생성하기 위해 시각 GUI 소프트웨어 를 사용하라: https://github.com/AlexeyAB/Yolo_mark
이것은 .jpg 이미지파일 각각에 대해 .txt 파일을 생성한다 - 동일 폴더에 동일한 이름으로, 하지만 .txt확장자, 그리고 파일로 쓴다: 이미지상의 개체 번호와 개체 좌표, 다른 행에 개체 각각에 대해:
<object-class> <x> <y> <width> <height>
여기에서:
<object-class>-(classes-1)을 개체번호 정수0부터<x_center> <y_center> <width> <height>- 이미지의 너비와 높이에 관련된 실수값, 이것은 0.0 ~ 1.0 이다- 예를들어:
<x> = <absolute_x> / <image_width>또는<height> = <absolute_height> / <image_height> - 주의:
<x_center> <y_center>- 이것은 사각형의 중심이다 (상-좌 모서리가 아니다)
예를들어 img1.jpg에 대해 담고있는 img1.txt가 생성된다:
1 0.716797 0.395833 0.216406 0.147222
0 0.687109 0.379167 0.255469 0.158333
1 0.420312 0.395833 0.140625 0.166667
build\darknet\x64\data\폴더에train.txt파일을 생성한다, 자신의 이미지 파일이름을 가진, 다른행에 각각의 파일이름,darknet.exe에 상대경로를 가진, 담고있는 예를 들면:
data/obj/img1.jpg
data/obj/img2.jpg
data/obj/img3.jpg
-
나선단에 대해 미리-벼림된 가중값(154 MB)을 내려받는다. 그리고
build\darknet\x64폴더에 넣는다. -
명령행을 사용하여 벼림을 시작한다:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74
리눅스에서 벼림하기위해 사용하는 명령: ./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74 (darknet.exe대신에 ./darknet사용)
yolo-obj_last.weights파일은 100번 반복마다build\darknet\x64\backup\에 저장된다yolo-obj_xxxx.weights파일은 1000번 반복마다build\darknet\x64\backup\에 저장된다- 손실-창을 해제하기 위해
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -dont_show사용, Amazaon EC2 클라우드처럼 감시없이 벼림하는 경우 - GUI없이 원격서버로 벼림하는 동안 mAP와 손실-챠트(Loss-chart)를 보기위해,
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -dont_show -mjpeg_port 8090 -map명령을 사용한다 그런다음 크롬/파이어폭스 브라우저에서http://ip-address:8090URL을 연다
8-1) 벼림을 위해 4세대마다 계산한 평균정밀도평균(mAP: mean Average Precisions)을 가짐(obj.data파일에 valid=valid.txt또는 train.txt을 설정) 그리고 실행: darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map
- 벼림이 완료된 후에 -
build\darknet\x64\backup\경로에서yolo-obj_final.weights결과를 얻는다
- 매 100번 반복후 중지할수 있다 그리고 나중에 이 시점부터 벼림을 시작한다. 예를들어, 2000번 반복후에 벼림을 중지할수 있다, 그리고 나중에
build\darknet\x64\backup\에서build\darknet\x64\로yolo-obj_2000.weights을 복사한다 그리고 이것을 사용하여 벼림을 시작한다:darknet.exe detector train data/obj.data yolo-obj.cfg yolo-obj_2000.weights
( 원본 저장소 https://github.com/pjreddie/darknet 의 가중값파일은 10,000번 반복마다 1번 저장된 것이다 if(iterations > 1000) )
- 또한 당신은 모두 45,000번 반복보다 빠르게 결과를 얻을수 있다.
알림: 만약 벼림하는 동안 avg(손실, 오차) 영역에 대하여 nan값을 봤다 - 그러면 벼림이 잘못된 것이다, 하지만 만약 nan이 다른 행에 있다 - 그러면 벼림이 잘 되는 것이다.
알림: 만약 자신의 구성파일에서 width= 또는 height=를 변경했다, 그러면 새로운 너비와 높이를 반드시 32로 나눌수 있어야 한다.
알림: 벼림후 검출을 위해 이런 명령을 사용한다: darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
알림: 만약 메모리 부족(Out of memory)이 발생한다, 그러면 .cfg파일에서 subdivisions=16을 키워야 한다, 32 또는 64: 연결 의 4행을 수정한다
5-2. 꼬맹이-욜로(tiny-yolo) 벼림하는 방법(자기맞춤 개체 검출을 위해)
위에 설명한것 처럼 욜로모형 전체에 대해 모두 동일 단계로 수행한다. 이것을 제외한 부문을 가지고:
- yolov3-tiny를 위한 기본 가중값파일을 내려받는다: https://pjreddie.com/media/files/yolov3-tiny.weights
- 명령을 사용하여 미리-벼림된 가중값
yolov3-tiny.conv.15를 가져온다:darknet.exe partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15 yolov3.cfg대신에cfg/yolov3-tiny_obj.cfg를 기반으로 자기맞춤 모형yolov3-tiny-obj.cfg을 만들어라- 벼림 시작:
darknet.exe detector train data/obj.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15
다른 모형을 기반으로 욜로를 벼림하기 위해( DenseNet201-Yolo 또는 ResNet50-Yolo ), 이 파일에 표시된대로 미리-벼림된 가중값을 내려받아 얻을수 있다: https://github.com/AlexeyAB/darknet/blob/master/build/darknet/x64/partial.cmd
만약 다른 모형을 기반으로 하지 않은 자기맞춤 모형을 만든다, 그러면 미리-벼림됨 가중값 없이 벼림할수 있다, 이때 뿌린 초기 가중값이 사용된다.
6. 언제 벼림을 중지해야 하는가
각 분류(개체)에 대해 보통 2,000번 반복이면 충분하다, 하지만 전체(자료집합 전체)로 적어도 4,000번 반복한다. 하지만 더 정밀한 정의를 위해 벼림을 중단 해야만 할때, 다음 설명을 사용하라:
- 벼림하는 동안, 다양한 오류지수를 볼 것이다, 그리고 0.XXXXXXX avg 가 더이상 줄지 않을때 멈춰야 한다:
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8
9002: 0.211667, 0.060730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
* **9002** - 반복 횟수(사리수, batch)
* **0.060730 avg** - 평균손실(오차) - **낮을수록, 더 좋다**
많은 반복에서 평균손실 0.xxxxxx avg 이 더이상 줄지않는 것을 봤을때 그때 벼림을 중지해야만 한다.
- 일단 벼림이 멈추면,
darknet\build\darknet\x64\backup에서.weights파일의 마지막 일부를 가져와야 한다, 그리고 그중에 최적을 선택한다:
예를들어, 9,000번 반복후에 벼림을 중지했다, 하지만 최적의 결과는 이전 가중값중에서 하나를 가질수 있다(7000, 8000, 9000). 이것은 심한(과도)적합으로 인해 발생될수 있다. 과도적합(Overfitting) 의 경우 벼림-자료집합에서 이미지로 개체검출을 할때, 모든 다른 이미지로 개체검출을 할수 없다. 반드시 이른 중지지점, Early Stopping Point 에서 가중값을 가져와야 한다:
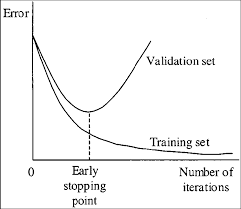
이른 중지지점(Early Stopping Point)에서 가중값을 가져오기 위해!
2-1) 먼저, 자신의 obj.data파일안에 검증 자료집합 valid = valid.txt에 경로를 반드시 지정해야 한다(valid.txt형식을 train.txt처럼), 그리고 만약 검증이미지가 없다면, 그냥 data\train.txt를 data\valid.txt로 복사한다.
2-2) 만약 벼림이 9,000번 반복후에 중지되었다면, 이전가중값 일부를 검증하기 위해 이 명령을 사용한다:
( 만약 다른 깃허브 저장소를 사용한다, 그러면 darknet.exe detector map… 대신에 darknet.exe detector recall… 을 사용한다 )
* `darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights`
* `darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weights`
* `darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights`
그리고 각 가중값(7000, 8000, 9000)에 대해 마지막 출력행을 비교한다:
가장높은 mAP(평균정밀도 평균, mean Average Precision) 또는 교차겹침결합(IoU, Intersect over Union)을 가진 가중값 파일을 선택한다
예를들어, 더큰 mAP 는 yolo-obj_8000.weights가중값이다 - 그러면 검출을 위해 이 가중값을 사용한다.
아니면 그냥 -map 표기를 하고 벼림한다:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map
주의:
-map 는 평균정밀도평균 mAP를 의미하는 map 임을 기억하라.
형식, 양식등을 의미하는 지도(map) 의미가 아님.
그러면 손실-챠트 창에서 mAP-챠트(적색)를 볼수있다. 평균정밀도 평균(mAP)는 valid=valid.txt파일을 사용하여 4세대(Epoch) 마다 계산된다 이것은 obj.data파일에 지정된 것이다(1세대(Epoch) = train.txt의 이미지수 / batch 반복)
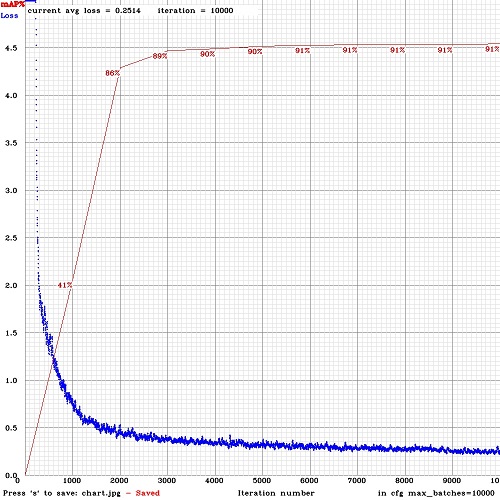
맞춤 개체검출 본보기: darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
* **IoU:** 개체의 교차겹침결합(Intersect over Union) 평균이다 그리고 특정한 문턱값 = 0.24 에 대한 검출이다.
* **mAP:** 각 분류에 대한 `평균정밀도(Average Precision)`의 평균(mean)값이다, 여기에서 `평균정밀도`는 동일등급을 위해 문턱이상(각 검출가능한) 각각에 대한 PR-곡선상 11 지점의 평균값이다(PascalVOC 관점에서 정밀도-기억(Precision-Recall), 여기에서 Precision = TP/(TP+FP) 그리고 Recall=TP/(TP+FN) ), 11 페이지:
http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
평균정밀도 평균(mAP)은 PascalVOC 경쟁(대회)에서 기본 정밀도 측정법 이다, 이것은 MS COCO 경쟁(대회)에서 AP50 측정법과 동일하다. 위키의 관점에서, 정밀도(Precision)와 기억(재현, Recall) 지표는 PascalVOC 경쟁(대회)과는 약간 다른 의미를 가진다, 하지만 교차겹침결합(IoU: Intersect over Union)은 항상 동일한 의미다.
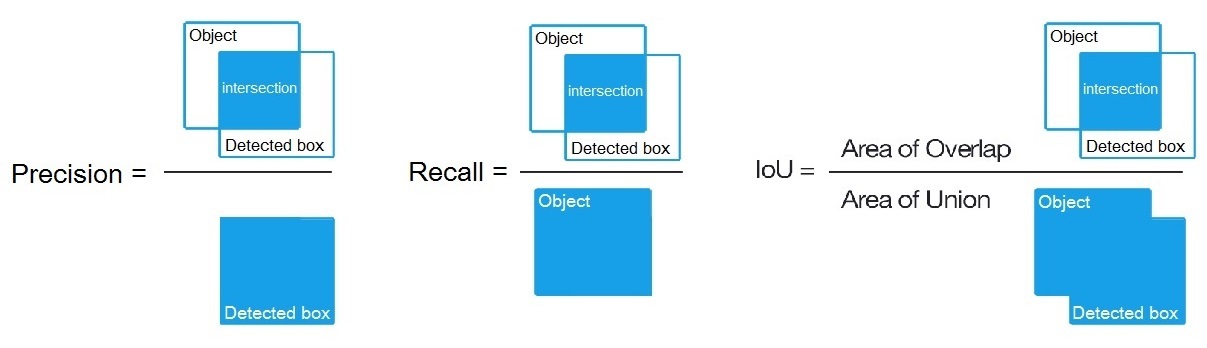
7. 물리 시각개체분류(Pascal VOC)로 mAP를 계산하는 방법
- PascalVOC-2007-test 로 평균정밀도평균(mAP: mean Average Precision)을 계산하기 위해:
- PascalVOC 자료집합을 내려받고, Python 3.x을 설치하고
2007_test.txt파일을 가져온다 여기에 설명된 대로:
https://github.com/AlexeyAB/darknet#how-to-train-pascal-voc-data - 그런다음
build\darknet\x64\data\폴더에 https://raw.githubusercontent.com/AlexeyAB/darknet/master/scripts/voc_label_difficult.py 파일을 내려받는다 그런다음difficult_2007_test.txt파일을 얻기 위해voc_label_difficult.py를 실행한다. - 주석을 해제하기 위해 이 줄에서
#문자를 제거한다:
https://github.com/AlexeyAB/darknet/blob/master/build/darknet/x64/data/voc.data#L4 (4행) - 그런다음 평균정밀도평균(mAP: mean Average Precision)을 얻기위한 2가지 방법이 있다:
ㄱ) 다크넷 + 파이썬 사용:build/darknet/x64/calc_mAP_voc_py.cmd파일 실행 -yolo-voc.cfg모형에 대해 mAP = 75.9%를 얻을 것이다.
ㄴ) 이 가지의 다크넷 사용:build/darknet/x64/calc_mAP.cmd파일 실행 -yolo-voc.cfg모형에 대해 mAP = 75.8%를 얻을 것이다.
( 이 글은 YOLOv2 416×416에 대해 mAP = 76.8% 값을 명시했다, 4 페이지 표-3: https://arxiv.org/pdf/1612.08242v1.pdf. 우리는 낮은값을 가진다 - 아마도 실제로 검출된 코드와 약간 다른 소스코드로 벼림된 모형이기 때문일 것이다 )
- 만약
tiny-yolo-voc.cfg모형에 대한 mAP를 얻기를 원한다, 그러면.cmd파일에서tiny-yolo-voc.cfg행을 주석해제 하고yolo-voc.cfg행을 주석처리 한다. - 만약 Python 3.x 대신에 Python 2.x를 가지고 있다, 그리고 만약 mAP를 얻기위해 다크넷+파이썬 방식을 사용한다, 그러면 자신의
.cmd파일에서reval_voc.py와voc_eval.py를 사용하라, 이 폴더의reval_voc_py3.py와voc_eval_py3.py대신에:
https://github.com/AlexeyAB/darknet/tree/master/scripts
7-2 맞춤 개체검출
맞춤 개체검출의 본보기: darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
<p align="center"> </p> </p> |
|---|
<p align="center"> </p> </p> |
8. 개체검출을 개선하는 방법
- 벼림 전:
-
자신의
.cfg파일에서random=1표시 설정 - 이것은 다른 해상도로 욜로를 벼림하여 정밀도가 증가된다: 연결 (788행) -
자신의
.cfg파일에서 망 해상도를 증가한다(height=608,width=608또는 모든 32의 배수값) - 정밀도가 증가할 것이다. -
.cfg파일의width와height를 위해 자료집합에 대한 고정자(anchor)를 다시계산 한다:darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416그런다음 자신의.cfg파일에서 3개의[yolo]단 각각에 동일한 9개의anchors(고정자)를 설정한다. -
모든 개체가 자신의 자료집합에 정해진 딱지인지 확인한다 - 자신의 자료집합에 딱지가없는것이 없어야 한다. 대부분의 벼림문제는 - 자신의 자료집합에 잘못된 딱지가 있다(변환 스크립트 일부를 사용하여 딱지를 얻었다, 다른 도구로 표식, 등등). 항상 다음을 사용하여 자신의 자료집합을 확인한다: https://github.com/AlexeyAB/Yolo_mark
-
자신의 벼림 자료집합은 다른 개체의 이미지를 포함한 것이 바람직하다 - 축척, 회전, 조명, 다른 쪽으로 부터, 다란 배경으로 - 가급적이면 각 분류에 대해 2,000개 다른 이미지 또는 그 이상을 가지고 있어야 한다, 그리고
2000*classes번 반복 또는 그 이상 벼림을 해야한다. -
자신의 벼림 자료집합은 검출을 원하지 않는 개체는 딱지가없는 이미지를 포함한 것이 바람직하다 - 경계상자 없는 음성표본(Negative Sample: 목표값이 0, 내용없는
.txt파일) - 개체가 있는 이미지와 마찬가지로 음성표본(Negative Sample)도 많이 사용한다 -
각 이미지에서 많은 수의 개체를 가지고 벼림을 위해,
.cfg파일에서 마지막[yolo]단 또는[region]에 참여(parameter)를max=200또는 높은 값으로 추가한다( YoloV3로 검출할수있는 개체 전체 최대개수는0,0615234375*(width*height)이다 여기에서width와height는.cfg파일에서[net](망정보) 단의 참여(parameter)이다 ) -
작은 개체애 대해 벼림을 위해 - https://github.com/AlexeyAB/darknet/blob/6390a5a2ab61a0bdf6f1a9a6b4a739c16b36e0d7/cfg/yolov3.cfg#L720 (720행) 대신에
layers = -1, 11을 설정한다 그리고 https://github.com/AlexeyAB/darknet/blob/6390a5a2ab61a0bdf6f1a9a6b4a739c16b36e0d7/cfg/yolov3.cfg#L717 (717행) 대신에stride=4를 설정한다. -
수정된 모형을 사용하여 작고 큰 개체 모두 벼림하기 위해:
- 전체 모형: 욜로 단 5개: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg
- 꼬맹이 모형: 욜로 단 3개: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny_3l.cfg
- Spatial-full 모형: 욜로 단 3개: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-spp.cfg
-
만약 왼쪽와 오른쪽 개체 분류 따라따로 구별하기 위해 모형을 벼림한다(left/right hand, left/right-turn on road signs, …) 그런다음 뒤집기 자료 증대를 해제하기위해 - 여기에
flip=0를 추가한다: https://github.com/AlexeyAB/darknet/blob/3d2d0a7c98dbc8923d9ff705b81ff4f7940ea6ff/cfg/yolov3.cfg#L17 (17행) -
일반 규칙 - 자신의 벼림 자료집합은 자신이 검출하고자 하는 개체의 상대적 크기를 설정해야 한다:
train_network_width * train_obj_width / train_image_width ~= detection_network_width * detection_obj_width / detection_image_widthtrain_network_height * train_obj_height / train_image_height ~= detection_network_height * detection_obj_height / detection_image_height
즉, 평가 자료집합에서 각 개체를 위해 벼림 자료집합에 상대크기가 거의 같은 개체가 적어도 하나는 있어야 한다:
object width in percent from Training dataset ~= object width in percent from Test dataset
즉, 만약 벼림 집합에 이미지의 80~90%를 점유하는 개체만 있다면, 그러면 벼림된 망은 이미지의 1~10%를 점유하는 개체는 감지할수 없다.
- 벼림 가속을 위해(검출 정밀도 감소됨) 전이학습(Transfer-Learning) 대신에 미세조정(Fine-Tuning)을 한다,
stopbackward=1참여 설정은 여기에: https://github.com/AlexeyAB/darknet/blob/6d44529cf93211c319813c90e0c1adb34426abe5/cfg/yolov3.cfg#L548 (548행)
그런다음 이 명령을 수행한다:./darknet partial cfg/yolov3.cfg yolov3.weights yolov3.conv.81 81이것은yolov3.conv.81파일을 생성할 것이다, 그런다음darknet53.conv.74대신에yolov3.conv.81가중값 파일을 사용하여 벼림한다.
- 벼림 후 - 검출을 위해:
-
자신의
.cfg에서 망 해상도를 높인다 (height=608와width=608) 또는 (height=832와width=832) 또는 (모든 32배수의 값) - 이것은 정밀도가 증가한다 그리고 작은 개체를 검출할수 있다: 연결(8행, 9행)- 이것은 망을 다시 벼림할 필요가 없다, 그냥 사용한다
.weights파일은 이미 416x416 해상도로 벼림되었다 - 하지만 더 좋은 정밀도를 얻으려면 높인 해상도 608x608 또는 832x832로 벼림해야 한다, 알림: 만약
메모리 부족, Out of memory오류가 발생단다 그러면.cfg에서subdivisions=16을 증가시켜야 한다, 32 또는 64: 연결(4행)
- 이것은 망을 다시 벼림할 필요가 없다, 그냥 사용한다
9. 개체의 경계상자를 표시하고 설명파일을 생성하는 방법
여기에서 Yolo v2 와 v3를 위한 개체의 경계상자 표시와 설명파일을 생성하기 위해 GUI-스프트웨어를 가진 저장소를 찾을수 있다: https://github.com/AlexeyAB/Yolo_mark
본보기 : 개체 2 분류(air, bird)를 위해 train.txt, obj.names, obj.data, yolo-obj.cfg, air1-6.txt, bird1-4.txt 그리고 Yolo v2 와 v3으로 이 이미지-집합을 벼림하는 방법은 train_obj.cmd
10. 욜로9000(Yolo9000) 사용
9,000개 개체를 동시에 검출과 분류를 한다: darknet.exe detector test cfg/combine9k.data cfg/yolo9000.cfg yolo9000.weights data/dog.jpg
-
yolo9000.weights- (186 MB Yolo9000 모형) 4 GB GPU-RAM 요구됨:
http://pjreddie.com/media/files/yolo9000.weights -
yolo9000.cfg- Yolo9000 구성파일, 또한 여기9k.tree와coco9k.map에는 경로가 있다 https://github.com/AlexeyAB/darknet/blob/617cf313ccb1fe005db3f7d88dec04a04bd97cc2/cfg/yolo9000.cfg#L217-L218 (217행, 218행)-
9k.tree- 9,418개 분류의 WordTree(단어가지) -<label> <parent_it>, 만약parent_id == -1그러면 이 딱지는 뿌리가 없다:
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.tree -
coco9k.map- MSCOCO 로 WordTree(단어가지)9k.tree에 80개 분류를 일치시킨다:
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/coco9k.map
-
-
combine9k.data- data 파일, 이것은 다음에 대한 경로이다:9k.labels,9k.names,inet9k.map, (자신의combine9k.train.list경로로 변경한다):
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/combine9k.data-
9k.labels- 9,418개 개체의 딱지:
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.labels -
9k.names- 9,418개 개체의 이름:
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.names -
inet9k.map- ImageNet 로 WordTree(단어가지)9k.tree에 200개 분류를 일치시킨다:
https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/inet9k.map
-
11. DLL로 욜로를 사용하는 방법
- 욜로를 C++ DLL 파일
yolo_cpp_dll.dll로 컴파일하기 위해 - MSVS 2015에서build\darknet\yolo_cpp_dll.sln파일을 열고, x64 와 Release 로 설정한다, 그리고 실행한다: 빌드 -> yolo_cpp_dll 빌드
- CUDA 10.0 이 설치되어 있어야 한다.
- cuDNN 사용을 위해: 프로젝트 -> 속성 -> C/C++ -> 전처리기 -> 전처리기 정의에
CUDNN추가
- 욜로를 자신의 C++ 콘솔응용프로그램에서 DLL 파일로 사용하기 위해 - MSVS 2015에서
build\darknet\yolo_console_dll.sln파일을 열고, x64 와 Release 로 설정한다, 그리고 실행한다: 빌드 -> yolo_console_dll 빌드
-
윈도우 탐색기에서
build\darknet\x64\yolo_console_dll.exe콘솔 응용프로그램을 실행할수 있다 이 명령을 사용하여:
yolo_console_dll.exe data/coco.names yolov3.cfg yolov3.weights test.mp4 -
자신의 콘솔응용프로그램을 실행한다 그리고 이미지파일 이름을 입력한다 - 각 개체에 대한 정보를 볼수있다:
<obj_id> <left_x> <top_y> <width> <height> <probability> -
간단한 OpenCV-GUI를 사용하기 위해
yolo_console_dll.cpp에서//#define OPENCV행을 주석해제를 해야한다: 연결(5행) -
동영상 파일로 검출을 위한 간단한 본보기 원본코드를 볼수있다: 연결(74행)
yolo_cpp_dll.dll-API: 연결(42행)
class Detector
{
public:
Detector(std::string cfg_filename, std::string weight_filename, int gpu_id = 0);
~Detector();
std::vector<bbox_t> detect(std::string image_filename, float thresh = 0.2, bool use_mean = false);
std::vector<bbox_t> detect(image_t img, float thresh = 0.2, bool use_mean = false);
static image_t load_image(std::string image_filename);
static void free_image(image_t m);
#ifdef OPENCV
std::vector<bbox_t> detect(cv::Mat mat, float thresh = 0.2, bool use_mean = false);
#endif
};